

Nous allons nous intéresser aujourd’hui à la problématique des tests dans le Big Data : vaste chantier sur un phénomène encore nouveau et pourvu d’innombrables challenges. Commençons d’abord par un petit rappel sur le Big Data pour que vous puissiez comprendre autant que possible comment le tester.
C'est quoi le Big Data ?
Avec l’essor d’Internet, la quantité de données au niveau mondial n’a fait qu’exploser de manière exponentielle. L’exemple des réseaux sociaux est toujours le plus impressionnant. On note ainsi qu’environ 3,4 millions de statuts Facebook sont générés par minute dans le monde et produisent dans le même moment plus de 4 giga-octets de données digitales.
Cette masse de données est telle que l’on ne peut plus l’exploiter avec les bases de données classiques (RDBMS) ou avec les systèmes de fichiers actuels.
C’est sous le terme « Big Data », signifiant « données massives » de manière littérale, que l’on regroupe ces ensembles de données.
Inventé par les géants du Web, le Big Data vise à répondre à la problématique dite des « 3V » de ces données, à savoir :
- Le Volume considérable à traiter;
- La Variété, les données proviennent de différentes sources. Elles sont donc de natures différentes :
- structurées (databases, ERP, CRM…),
- semi-structurées (fichiers csv, xml, json,...)
- non structurées (vidéo, audio, image…);
- La Vélocité, qui correspond à la capacité à traiter rapidement ces données.
Hadoop, la principale plateforme du Big Data.
Sponsorisé par Apache Software Foundation, Hadoop est un framework open-source qui offre un espace de stockage massif pour tous les types de données, connu sous le nom de HDFS (Hadoop Distributed File System). Il s'accompagne d'un traitement spécifique distribué d’une immense puissance connue sous le nom de MapReduce. Dans cet article, nous partirons du principe que les tests à mener sont effectués sur cette plateforme.
Une plateforme Big Data en entreprise
On pourrait regrouper en trois grandes étapes l’écosystème Big Data avec Hadoop dans une entreprise. L’image suivante illustre ces trois étapes :
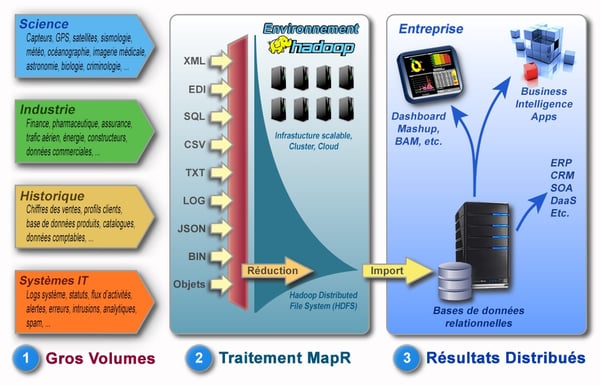
source : http://www.astrosurf.com/luxorion/big-data-mining3.htm
La première étape consiste à récupérer toutes les données provenant des différentes sources que l’on souhaite stocker dans notre système Hadoop. On récupère l’ensemble des données qui nous intéresse généralement au travers d’un ETL. Puis on les injecte dans le système HDFS qui se chargera de les stocker de manière distribuée via ce que l’on appelle des nœuds (nodes en anglais).
L’étape suivante consiste alors à utiliser MapReduce, le modèle de programmation qui permettra de traiter une requête de manière parallélisée sur l’ensemble des nœuds (fonction map) et ensuite d’agréger les données (fonction reduce).
Enfin, la dernière étape est d’exploiter les données récupérées en les envoyant par exemple dans un datawarehouse pour des fins de reporting.
C'est bien beau, mais comment se positionne le testing dans tout cela ?
Eh bien nous allons être transparents, ici le sujet se complique. Le Big Data, initialement adressé à des développeurs, traite par définition une masse colossale de données qui n’est justement pas exploitable en l’état, et il n’y a pas encore assez de recul pour en déduire une méthode certaine, outillée qui plus est.
Cela étant, nous pouvons tout de même établir plusieurs principes de test qui s’appliqueront dans la majorité des cas :
-
Validation des données pré-Hadoop
Consiste à vérifier que l’on récupère bien toutes les données souhaitées des systèmes sources, que l’on ne récupère pas les autres données, mais également à assurer qu’il n’y a pas eu de corruption de données au passage et qu’elles sont bien stockées au bon endroit sur HDFS. Concrètement, cela sous-entend souvent de valider l’ETL. On parlera dans la suite de ce billet des deux techniques de test à privilégier et des outils associés pour la validation de données. -
Validation du MapReduce
Ici, il faut valider que votre ou vos traitements MapReduce codés par vos développeurs fonctionnent bien. Le but est de vérifier à votre niveau :- Que les paires clefs/valeurs renvoyées par MapReduce sont bien générées;
- Qu’il n’y a pas eu d’erreur lors du traitement;
- Que les règles business spécifiées ont bien été appliquées.
Pour vérifier dans les faits le MapReduce, il est important ici d’utiliser des tests boîte blanche via MRUnit, une déclinaison du JUnit tant utilisé mais pour MapReduce. Ceci implique d’avoir un testeur autant formé que votre développeur à Hadoop, et bien sûr des connaissances en Java.
-
Validation du Data Storage
Enfin, nous validons ici la partie consistant à stocker la donnée de sortie de MapReduce soit sur HDFS à nouveau, soit après transfert vers un système tierce, généralement de type datawarehouse. Les principes sont relativement identiques, à savoir :- On s’assure que la donnée est bien stockée et au bon endroit;
- On valide l’intégrité des données;
- On valide qu’il n’y a pas eu de corruption de donnée.
-
Validation des Reports
Selon les projets ou entreprise, la partie reporting et ses corollaires (business intelligence) est gérée directement dans le cadre du projet Big Data. Si cela est vrai pour vous, alors cette partie-là doit être vérifiée expressément, comme dans le cas d’un projet classique d’analyse de données. -
Validation des autorisations
Comme dans tout système de fichier classique, HDFS est un système comportant des groupes d’utilisateurs, des utilisateurs et des autorisations spécifiques. Cette étape peut être importante à valider, notamment en fonction de la sensibilité des données.
Autres types de tests à prendre en compte et pas des moindres, ce sont les tests de performances au sens large et les tests de failover (comprendre reprise sur incident).
-
Tests de performance
Comme vous l’aurez compris via les « 3V », la performance d’une plateforme Hadoop est essentielle pour répondre à l'exigence de « Vélocité ». Il convient donc de tester la performance de l’acquisition des données de vos systèmes sources, la durée des jobs MapReduce, de l’utilisation des disques etc… Cela peut notamment être effectué avec JMeter. -
Tests de failover
Nous pensons qu’il est important, dans ce type d’architecture complexe objectivé sur une disponibilité de 100% (et non 99,9%), d’assurer que la reprise sur incident s’effectue bien, notamment sur la partie HDFS et la gestion des nœuds. Vous devez tester qu’en cas d’échec d’un nœud, le process de récupération des données est bien initialisé, que les données ne sont pas corrompues, que la réplication des données est bien faite, et que les métriques Recovery Point Objective (RPO) et Recovery Time Objective (RTO) sont bien récupérées. Pour rappel ces indicateurs sont les indicateurs de sécurité en cas de sinistre.
Et comment valider une telle masse de données ?
Malheureusement, Il n’y a pas de miracle, il nous est impossible de valider de manière certaine l’ensemble des cas amenant à une mauvaise donnée, donnée incomplète, corrompue etc. Mais, il est tout de même possible de valider au travers de deux méthodes, qui ont fait leur preuve :
-
L'échantillonage
Ah ce bon vieux échantillon de données ! Même si dans un système classique un échantillonnage peut être représentatif de 50, 60, 80% du panel, ici rassurez-vous (pas) nous n’atteindrons peut-être qu’1% du panel, mais c’est déjà suffisant pour tester et cela reste le moyen le plus utilisé pour un testeur fonctionnel qui, rappelons-le, doit déjà comprendre en parallèle comment fonctionne la plateforme Big Data. -
Le MINUS (ou EXCEPT)
Cette méthode provient du SQL et permet sur un plus gros volume de comparer les volumes sources avec les volumes cibles. Elle a pour but, après avoir comparé les résultats de deux requêtes, de mettre en visibilité les enregistrements uniquement présents dans la première requête. Il suffit alors de l’appliquer à la fois dans le sens « Source vers Cible » et « Cible vers Source » pour obtenir le delta entre les deux systèmes. Cela peut être puissant mais attention tout de même, cette méthode ne doit jamais être la seule sur laquelle vous reposer car elle amène plusieurs problèmes :- Gourmand en ressources et consommateur en temps
- Ne fait pas apparaître les données dupliquées, le minus ne fait apparaître qu’une occurrence de chaque ligne
- Potentiellement des faux positifs en résultat
Quel outillage pour nous aider ?
Là encore, ce n’est pas Byzance. Tous les sites et blogs vous parleront de 3 outils Testing-whiz, QuerySurge et Tricentis qui servent de référence aujourd’hui pour l’automatisation de vos tests. Nous ajouterons à cela deux outils :
- MRUnit pour les tests unitaires de MapReduce, indispensable pour vos développeurs et peut-être pour les testeurs les plus aguerris !
- Talend, lui-même ETL, mais qui permet également dans sa suite de valider la qualité de données (une version client lourd gratuite existe).
Le Big Data amène avec lui beaucoup de défis pour nous, testeurs, de part sa nouveauté et sa complexité. Dans vos équipes, nous ne pouvons que vous recommander de former vos testeurs autant que les développeurs au Big Data et surtout au système utilisé par votre entreprise ou vos clients, de sélectionner des profils techniques car il faudra à quasi toutes les étapes de test mettre les mains dans du code et dans des architectures distribuées complexes. Pour le reste, libre à vous d’innover pour trouver de nouvelles façons d’appréhender un système Big Data, d’autant que mêmes les systèmes de stockage, framework, langages sont en constante évolution depuis plusieurs années. Et surtout…partagez à la communauté vos trouvailles !